In this post, we break down Perception Language Models (PLMs), a new family of open-source vision-language models (VLMs) from Meta designed for advanced video and image understanding, introduced in a recent paper titled “PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding”.

Introduction
Vision-language models (VLMs), are a key part of the AI landscape today. These models combine text, images and even videos, to generate meaningful insights for multimodal inputs. This is useful for tasks like image captioning, visual question answering, video understanding, multimodal reasoning and more. However, the most advanced vision-language models remain closed-source. While strong open-source vision-language models exist, they are primarily trained using knowledge distillation from proprietary models. The proprietary black-box models are used to label the training data for the open-source model. In essence, these models learn to mimic the outputs of closed-source models rather than innovating independently. While this approach is useful for creating capable open-source vision-language models, it does not contribute much to the scientific progress of the open-source community.
The PerceptionLM paper by Meta bridges this gap. The paper describes the process of building a Perception Language Model (PLM) from scratch, without relying on closed-source black-box models, to push the research community forward. Now that we understand the motivation, let’s move on to understand the PLM architecture.

Perception Language Models High-Level Architecture

At the core of the Perception Language Model (PLM), we have a pretrained large language model (LLM). The one used in the paper is Llama3. We mentioned that the input can combine multiple modalities. Specifically, the model should handle text, images, and videos. Clearly there is a gap here since the LLM cannot just take images and videos as input.
To bridge this gap, the PLM has another key component – a vision encoder. Specifically, the one used in the paper is called Perception Encoder (PE). This is a pretrained model that is detailed in another paper. The role of the perception encoder is to extract visual features from images and videos. The visual features are embeddings that capture the semantics of the input.
Ok, but the LLM still cannot process these raw visual embeddings directly. For this reason, they are passed through a projector. Essentially, the projector is a small network, a two-layer MLP, which transforms the visual embeddings into the embeddings space of the LLM.
The text prompt is tokenized using Llama3’s built-in tokenizer. The projected visual embeddings and the token embeddings are merged and injected into the LLM together. This allows the LLM to process multiple input types simultaneously. And after training, it enables multimodal reasoning.
Perception Language Model Sizes
Meta developed PLMs in multiple sizes.
- LLaMA 3.2 1B and 3B were paired with a large perception encoder called PE-L, with 0.3 billion params.
- LLaMA 3.1 8B was paired with a giant perception encoder called PE-G, with 1.9 billion params.
High-Resolution With Dynamic Tiling
Another note about the architecture is the PLM ability to support high-resolution images. This is achieved using dynamic tiling. The perception encoder only support images up to a certain resolution. To be able to process images of higher resolution, dynamic tiling splits large images into smaller tiles. Each tile then undergoes average pooling to further reduce its resolution, where each 2 X 2 pixel block is replaced with the average value.
For video, 32 video frames are used, which also undergo the same pooling process.
Perception Language Models Training Process

The training process consists of three stages, which we can learn about using the above table from the paper.
Stage 1 – Warmup On Images Synthetic Data

The first stage is called a warmup stage. In this stage, only the projector component is trained, while both the vision encoder and the LLM remain frozen. The goal of this phase is to warm up the newly initialized parameters of the projector, which is the only component which is not already pretrained, and to improve the stability for later stages.
The training data in this stage consists of 1 million images. The images are small enough to be processed without dynamic tiling or pooling. These images are paired with synthetic captions which the LLM should predict using a next-token prediction objective.
Synthetic Data Generation
An important note is that the synthetic captions are not generated using a closed-source vision-language model. This would miss the goal of creating a fully open model. Instead, a text-only LLM generates captions without any visual inputs. To generate the captions, the LLM is fed with metadata and captions from the original images dataset, and more interestingly, also with text that is extracted from the images using optical character recognition (OCR).
Stage 2 – Large-Scale Training On Images & Videos Synthetic Data
The second stage is referred to as midtraining. In this stage, the vision encoder and the LLM are no longer frozen, and they are now trained jointly with the projector, allowing the model to refine the alignment between visual and textual representations.
Now, the model is trained on a significantly larger dataset of 64.7 million samples, that include both images and videos, with more diverse image domains. In addition to synthetic captions, synthetic questions and answers are also paired with the samples, also created using an LLM.
In this stage, the images are split up to a maximum of 16 tiles and 16 frames for videos. Each tile and video frame undergo average pooling for downsampling.
Synthetic Data Limitation

The synthetic data only helps to bring the model up to a certain limited level. In the above figure from the paper, we see the average error over video question and answer samples as training progresses. The three colors represent the different model sizes, and the black line represents the overall scaling trend.
The upper line, labeled Hard QA, tracks the errors in challenging video tasks. The graph shows that the error remains significant throughout the entire training progress. Let’s see how this is tackled in the third stage.
Stage 3 – SFT On Human-Annotated Data
In the final stage, the model is trained on higher-resolution images, using dynamic tiling with up to 36 tiles, and with 32 video frames for videos. Like in the second stage, each tile and video frame undergo average pooling.
The dataset in this stage is one of the key contributions of this paper. It contains 14 million human-annotated samples including challenging video tasks. Rather than next-token prediction, in this stage the model is trained using supervised fine-tuning (SFT), where the model is expected to generate the answer for question-and-answer samples. However, the dataset also contains more complex tasks, which we can learn about using the following figure from the paper.
Human-Annotated Dataset Examples

On the left, we see an example of a fine-grained question-and-answer task. The question asks a fine-grained detail about the video, regarding the direction in which the paper in the video is folded. The human-annotated answer specifies with details how the paper is folded.
On the right, we see an example for a sample with event timestamp annotations. Given a spatial location of the dog, its actions are captioned across the video frames. Such samples are converted into multiple SFT tasks, where the model is fed with the video and part of the annotated information, and is tasked with completing the missing information. For example, assigning timestamps to events given their captions, or generating captions for given timestamps.
Training on these more challenging samples significantly improves the model capabilities.
Perception Language Models Performance
Let’s review some of the results presented in the paper.
Image Benchmarks
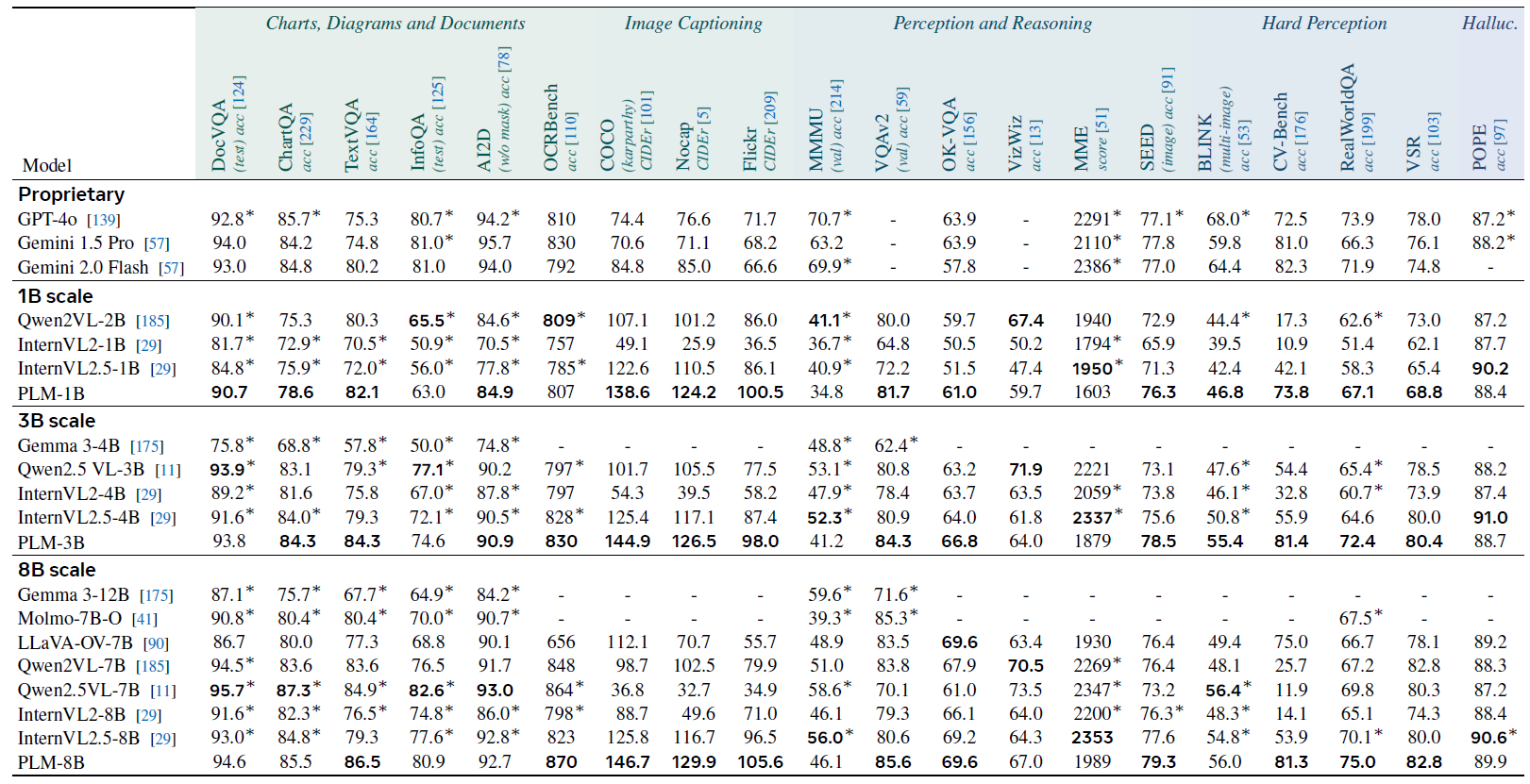
In the above table, we can see image benchmark results comparing proprietary models, strong open-source alternatives, and Perception Language Models of similar sizes. Overall, the perception language models achieve competitive performance across all benchmarks.
The benchmarks are divided into categories, and we can see that for image captioning and hard perception categories, perception language models outperform the existing state-of-the-art results. Overall, without relying on data from proprietary models, perception language models achieve very impressive results.
Video Benchmarks

Another interesting table shows the results on video benchmarks. Similar to the image benchmark results, here as well perception language models achieve competitive results across the board, and outperforming the state-of-the-art results in part of the benchmarks.
References & Links
- Paper
- Models & Code
- Join our newsletter to receive concise 1-minute read summaries for the papers we review – Newsletter
All credit for the research goes to the researchers who wrote the paper we covered in this post.
